
Database
Charindex Sql Function: SQL Server offers a variety of functions to assist developers in querying and manipulating data. Among these, the CHARINDEX SQL function stands out for its utility in string manipulation. It plays a crucial role in finding the position of a substring within a given string, thus aiding in data parsing and enhancing data retrieval processes.
- Key Takeaways:
- Master the syntax and parameters.
- Explore basic and advanced usage scenarios.
- Learn how to identify and avoid common mistakes.
- Delve into performance considerations and explore alternative functions.
Introduction to CHARINDEX SQL Function
Definition and Use Cases
In SQL operations, especially when dealing with string data, the CHARINDEX function emerges as a significant tool. It efficiently finds the starting position of a specified substring within a given string, returning the position of the first occurrence. This functionality proves indispensable in various real-world scenarios, such as data cleaning, data extraction, and pattern matching.
Importance in SQL operations
Syntax and Parameters of CHARINDEX SQL
Understanding the syntax and parameters of the CHARINDEX SQL function is the first step towards its effective utilization. Here is the generic syntax:
CHARINDEX ( substring, string, [start_position] )
Parameters Explanation
- substring: The substring to search for within the string.
- string: The string in which to search for the substring.
- start_position (optional): The position in the string where the search should begin.
| Parameter |
Description |
| substring |
The sequence of characters to search for. |
| string |
The string within which to search. |
| start_position |
(Optional) The position to start searching from. |
Basic Examples and Usage
Understanding the basic usage of the CHARINDEX function becomes straightforward with a few examples. Here, we demonstrate simple scenarios where CHARINDEX proves to be useful.
-- Example 1: Finding a substring within a string
SELECT CHARINDEX('SQL', 'Learning SQL Server');
-- Returns: 10
-- Example 2: Specifying a start position
SELECT CHARINDEX('SQL', 'Learning SQL Server', 11);
-- Returns: 0
Common Mistakes and Errors
Common Mistakes
- Ignoring Case-Sensitivity: Since the CHARINDEX function performs a case-insensitive search, overlooking this can lead to unexpected results.
- Overlooking Start Position: One should use the optional start position parameter cautiously, as it can alter the result.
Error Handling
- Incorrect Syntax: It’s crucial to ensure the correct syntax to avoid runtime errors.
- Non-Existent Substring: CHARINDEX returns 0 when the substring doesn’t exist within the string, which should be handled appropriately in your code.
Continuing from the basics, this part delves into the advanced usage of CHARINDEX, performance considerations, alternative functions, and video tutorials to help you better understand CHARINDEX. Additionally, it addresses frequently asked questions surrounding CHARINDEX functions to clarify common misconceptions.
Advanced Usage of CHARINDEX SQL
The CHARINDEX function goes beyond merely locating a substring within a string. It can be paired with other SQL functions to carry out complex string manipulations.
Using CHARINDEX with Other SQL Functions
- Combining with SUBSTRING: CHARINDEX can be used alongside SUBSTRING to extract a portion of text based on certain conditions.
- Utilizing with PATINDEX: Similar to CHARINDEX, PATINDEX can be used but it offers pattern matching, providing a level of flexibility.
Complex Examples
Here are some complex examples illustrating how CHARINDEX function can be used with other SQL functions:
-- Extracting domain from email
DECLARE @Email VARCHAR(100) = '[email protected]';
DECLARE @Domain VARCHAR(100);
SET @Domain = SUBSTRING(@Email, CHARINDEX('@', @Email) + 1, LEN(@Email));
SELECT @Domain; -- Output: example.com
Performance Considerations
Performance Impact
- Execution Time: Execution time could increase with larger strings or a higher number of records.
- Server Load: Heavy usage of CHARINDEX in SQL may lead to an increased server load.
Optimizing Queries using CHARINDEX
- Indexing: Proper indexing can help optimize queries using CHARINDEX.
- Avoiding Full Table Scans: Minimizing full table scans by filtering the data can also improve performance.
Alternatives to CHARINDEX Function
Exploring alternative functions that can be used in place of or along with CHARINDEX SQL:
- PATINDEX: This function allows pattern matching, which CHARINDEX in SQL does not support.
- POSITION: Similar to CHARINDEX, but follows a different syntax.
Frequently Asked Questions (FAQs)
What makes CHARINDEX SQL unique compared to other string functions?
CHARINDEX SQL is unique for its ability to locate a substring within a string, which is crucial for string manipulation tasks.
How can I optimize queries using CHARINDEX SQL?
Optimizing queries with CHARINDEX SQL involves proper indexing and avoiding full table scans wherever possible.
What are some common use cases for CHARINDEX SQL?
Common use cases include data parsing, pattern matching, and data extraction.
Are there any performance concerns with CHARINDEX SQL?
Yes, execution time and server load are two performance concerns with CHARINDEX SQL.
What are some alternatives to CHARINDEX SQL?
PATINDEX and POSITION are two notable alternatives to CHARINDEX SQL.

Database
SQL trim method: SQL, being a powerful language for managing data in databases, provides a variety of functions to manipulate strings, and among them, the SQL TRIM function holds a notable place. This function is crucial for cleaning up data and ensuring consistency across the database.
Key Takeaways
- The SQL TRIM function is essential for removing unwanted characters from strings, aiding in data consistency.
- Understanding and effectively utilizing TRIM, along with other similar functions like LTRIM and RTRIM, can significantly enhance data manipulation capabilities.
- Practical examples and common use cases further illustrate the importance and utility of the TRIM function in SQL.
Core Functionality of SQL TRIM
The SQL TRIM function is used to remove specified characters, or spaces by default, from the beginning (leading) and end (trailing) of a string. The basic syntax of the TRIM function is as follows:
TRIM ([characters FROM] string)
- Removing Leading and Trailing Spaces
The most common use of the TRIM function is to remove leading and trailing spaces from a string. This is crucial for data consistency, especially when comparing strings or saving data to a database.
SELECT TRIM (' Hello World ') AS TrimmedString;
In the above example, the TRIM function will return ‘Hello World’ without the leading and trailing spaces.
Comparing SQL TRIM to Other Functions
The SQL language has other functions similar to TRIM, which also help in manipulating strings.
- LTRIM and RTRIM Functions
The LTRIM (Left Trim) and RTRIM (Right Trim) functions are used to remove leading and trailing spaces respectively. While TRIM handles both sides of the string, LTRIM and RTRIM are used when the requirement is to remove spaces from only one side.
SELECT LTRIM(' Hello World') AS LeftTrimmedString;
SELECT RTRIM('Hello World ') AS RightTrimmedString;
Advanced Usage of SQL TRIM
The SQL TRIM function is not limited to just removing spaces; it can also be used to remove other specified characters from a string. This makes it a versatile tool for data cleaning and manipulation in SQL.
- Handling Special Characters
SELECT TRIM('x' FROM 'xxxHello Worldxxx') AS TrimmedString;
In this example, the TRIM function is used to remove the character ‘x’ from the beginning and end of the string.
- TRIM in Different SQL Dialects (Transact-SQL, PL/SQL, MySQL)
The implementation and usage of the TRIM function may slightly vary across different SQL dialects. For instance, the syntax for using TRIM in MySQL might be slightly different from that in Transact-SQL or PL/SQL.
Practical Examples
Practical examples provide a better understanding of how the TRIM function can be utilized in real-world scenarios.
- Removing Unwanted Characters from Data
In the above example, the TRIM function is used to remove the exclamation mark from the beginning and end of the string.
- Cleaning up Data using TRIM
Cleaning up data is crucial in database management to ensure consistency and accuracy of data. The TRIM function plays a significant role in this regard by removing unwanted characters from data.
Oracle SQL
Common Pitfalls and Best Practices
- Performance Considerations
It’s essential to consider the performance implications when using the
TRIM function, especially in large databases. Overuse or incorrect use of TRIM can lead to performance issues.
- Common Mistakes to Avoid
Some common mistakes include not specifying the characters to be removed when necessary, leading to unexpected results.
What is SQL Transaction?
Frequently Asked Questions (FAQs)
What is the main purpose of the SQL TRIM function?
The main purpose of the SQL TRIM function is to remove specified characters, or by default spaces, from the beginning (leading) and end (trailing) of a string.
How does the SQL TRIM function compare to LTRIM and RTRIM?
SQL TRIM function can remove characters from both the beginning and end of a string, whereas LTRIM and RTRIM are used to remove spaces from the left and right of a string, respectively.
Can the TRIM function remove characters other than spaces?
Yes, the TRIM function can remove specified characters other than spaces from a string by providing the character(s) as an argument.
Is the syntax for TRIM the same across different SQL dialects?
The basic syntax is similar, but there might be slight variations across different SQL dialects like Transact-SQL, PL/SQL, or MySQL.
How can I use the TRIM function to improve data consistency in my database?
By using the TRIM function to remove unwanted characters or spaces from your data, you can ensure more consistent data entry and reduce potential errors in your database.
What are some common mistakes to avoid when using the TRIM function?
Common mistakes include not specifying the characters to be removed when necessary, and assuming TRIM will only remove spaces when other characters might also need to be addressed.
Can the TRIM function be used in conjunction with other SQL functions?
Yes, the TRIM function can be used alongside other SQL functions in a query to manipulate and format data as required.
What is the performance impact of using the TRIM function in a large database?
The performance impact can vary, but excessive or incorrect use of the TRIM function in a large database can potentially lead to performance issues.
Are there any alternatives to the TRIM function for removing spaces in SQL?
Yes, besides TRIM, functions like LTRIM and RTRIM, or even the REPLACE function can be used to remove spaces or replace characters in a string.
Can the TRIM function handle multiple characters for removal at once?
Yes, the TRIM function can handle multiple characters for removal if they are specified in the function argument.

Database
Sql Between Dates: The ability to query data within a specific date range is crucial in database management. It helps in narrowing down the data for analysis, reporting, or any other operations necessary for business processes. SQL provides an efficient way to filter data between dates using the BETWEEN operator. This article will delve into the application of the SQL BETWEEN operator in handling date ranges, its syntax, and various examples to illustrate its utility.
- Key Takeaways
- Understanding the syntax and application of SQL BETWEEN operator.
- Practical examples to retrieve data between dates.
- Common use cases for querying date ranges in SQL.
- Optimizing your queries for better performance.
Introduction to SQL BETWEEN Operator
SQL is a powerful language used in managing relational databases. One of its strong suits is the ability to filter data using various operators, among them the BETWEEN operator. This operator is used to filter the data within a specified range, which can be numbers, text, or dates.
- Relevance of Date Range Queries
- Historical data analysis
- Real-time reporting
- Data auditing
Syntax and Usage of BETWEEN Operator
The basic syntax of the BETWEEN operator is as follows:
expression BETWEEN low AND high;
Examples of BETWEEN Operator with Dates
SELECT * FROM Orders WHERE OrderDate BETWEEN '2022-01-01' AND '2022-12-31';
This query will retrieve all orders placed within the year 2022.
Common Use Cases for Date Range Queries
Being able to query data within a specific date range is crucial in various scenarios such as:
- Financial reporting
- Inventory management
- User activity tracking
Optimizing Date Range Queries
It’s important to ensure your queries are optimized to run efficiently. Some tips include:
- Indexing the date column
- Avoiding functions on the date column in the WHERE clause
Practical Examples and Scenarios
Let’s look at some practical examples and scenarios where querying date ranges in SQL is necessary.
- Example 1: Financial Reporting
- Quarterly financial reports
- Yearly tax calculations
- Example 2: User Activity Tracking
- Monitoring user logins
- Analyzing user activity trends
Incorporating BETWEEN Operator in Different SQL Databases
Different SQL databases may have slight variations in how they handle date range queries.
- MySQL and Date Range Queries
- Using the DATE_FORMAT function for better control over date formats.
- SQL Server and Date Range Queries
- Utilizing the CAST and CONVERT functions for date manipulation.
Handling Different Date Formats
SQL is flexible in handling different date formats which is crucial for working with diverse databases. The standard date format is ‘YYYY-MM-DD’, but variations exist and may require conversions for accurate querying.
Converting Date Formats
SQL provides functions like CONVERT() and CAST() to change date formats. These functions are handy when dealing with date strings or different date format standards.
-- Example using CONVERT()
SELECT CONVERT(VARCHAR, GETDATE(), 101); --Converts current date to MM/DD/YYYY format
Dealing with NULL or Missing Dates
In a real-world database, it’s common to encounter missing or NULL date values which can affect the accuracy and performance of your date range queries.
Strategies to Handle NULL Dates
- Utilizing the
COALESCE() function to replace NULLs with a specified value.
- Implementing data validation checks to prevent NULL date entries.
Performance Optimization Strategies
Optimizing the performance of your date range queries is crucial to ensure they execute efficiently and return the expected results promptly.
Indexing Date Columns
Creating indexes on date columns can significantly enhance the query performance.
Avoiding Full Table Scans
Full table scans are performance killers, especially in large databases. Use indexed columns in the WHERE clause to avoid full table scans.
Error Handling in Date Range Queries
Errors are inevitable in SQL queries. Understanding common errors and how to troubleshoot them will ensure your date range queries run smoothly.
Common Errors
- Incorrect date format
- Missing or NULL date values
Utilizing Advanced SQL Features
Advanced SQL features like Common Table Expressions (CTEs) and Window Functions can be employed to enhance your date range querying capabilities.
Common Table Expressions (CTEs) and Date Range Queries
-- Example using CTE
WITH DateRange AS (
SELECT OrderDate FROM Orders
WHERE OrderDate BETWEEN '2022-01-01' AND '2022-12-31'
)
SELECT * FROM DateRange;
Frequently Asked Questions (FAQs)
How can I optimize the performance of date range queries in SQL?
Utilizing indexing, avoiding full table scans, and employing advanced SQL features like CTEs can optimize the performance of date range queries.
What are the common errors encountered in date range queries?
Common errors include incorrect date format and missing or NULL date values. Understanding and addressing these errors is crucial for accurate querying.

Database
DBF to SQL: DBF (Database File) is a file format originally used by dBASE, a database management system software. Over time, many organizations have migrated from using DBF to more modern database systems like SQL (Structured Query Language) to better manage their data. Converting DBF to SQL is a significant transition that necessitates meticulous planning and a well-structured approach to ensure data integrity and system performance.
Key Takeaways:
- Selecting the right conversion tool is crucial for a smooth transition from DBF to SQL.
- A structured migration process minimizes the risk of data loss or corruption.
- Verification and validation post-migration ensure data integrity and accurate representation in the new SQL database.
- Familiarizing oneself with common FAQs can prepare one for potential challenges during the migration process.
Choosing the Right Conversion Tool
Selecting a reliable and efficient conversion tool is critical to simplify the DBF to SQL Server conversion process. The right tool can streamline the migration process, providing a powerful and user-friendly solution with features like intuitive user interfaces and efficient data mapping capabilities.
Features of a Good Conversion Tool
- Intuitive User Interface: A user-friendly interface simplifies the conversion process, making it accessible even for individuals with minimal technical expertise.
- Efficient Data Mapping Capabilities: Effective data mapping is crucial to ensure that data in DBF files accurately corresponds to the right fields in the SQL database.
- Support for Various Data Types: The conversion tool should handle different data types and indices accurately to prevent any data loss or corruption.
Here’s a table summarizing some popular conversion tools:
| Tool Name |
Supported Databases |
Key Features |
| Full Convert |
SQL Server, MySQL, Oracle |
Easy-to-use, High-speed conversion, Supports a wide range of databases |
| DBF Commander |
SQL Server |
User-friendly, Supports advanced data mapping |
| SQL Server Migration Assistant |
SQL Server |
Microsoft-supported, Comprehensive data type mapping |
The Migration Process: A Step-by-Step Guide
Migrating from DBF to SQL involves several steps to ensure data integrity and accurate representation in the new database system.
Initiating the Import Process
- Navigate to Object Explorer in your SQL Server Management Studio (SSMS).
- Right-click on the database where you want to import the data, hover over “Data Pump,” and then select “Import Data.”
Configuring Source File Settings
- Choose the DBF format for import.
- Provide the path and name of your DBF source file.
Setting Up the Destination Database
- Specify the SQL Server connection details.
- Decide whether you’re importing the data into a new table or an existing one.
Formatting Options
- Set the correct encoding.
- Decide whether to import rows that were marked as deleted in the original DBF file.
Data and Column Settings
- Configure formats for null strings, separators, and date/time formats.
- Adjust format settings for individual columns.
Mapping Columns
- Align the source columns with the target columns in the SQL database.
- Auto-create columns if you’re importing into a new table.
Import Modes and Additional Settings
- Choose the import mode: Append, Update, or Delete.
- Opt for bulk insert options to speed up the import process.
Output and Error Handling
- Choose output handling: open the data import script in an internal editor, save it to a file, or directly import the data into the database.
- Specify how errors should be handled during the import process.
Advanced Tips for a Smooth Transition
Transitioning from DBF to SQL can be a daunting task, but with the right approach and tools, it can be simplified.
Automated vs Manual Mapping
- Automated mapping can significantly speed up the process but may not always cater to specific requirements.
- Manual mapping provides a higher degree of control but can be time-consuming.
Handling Large DBF Files
Error Handling and Troubleshooting
- Keeping a detailed log of the conversion process can help in identifying and troubleshooting issues.
- Having a rollback plan in place in case of critical errors is prudent.
- Logging: Maintain detailed logs to identify and resolve issues during the migration process.
- Rollback Plan: Having a rollback plan ensures that you can quickly revert changes in case of critical errors.
Case Study: Converting a Complex DBF Database to SQL
A real-world scenario showcasing the challenges and solutions encountered during the conversion of a complex DBF database to SQL.
In a real-world scenario, a medium-sized enterprise had been using a DBF database for over a decade. However, with the expansion of business and increased data requirements, they found it necessary to migrate to a SQL Server database.
Scenario Outline
- Initial Database Size: 20 GB DBF database
- Target: Migrate to SQL Server with minimal downtime
- Tools Used:DBConvert for the initial data migration, followed by manual data mapping and verification
Challenges Encountered
- Data Mapping: Manual mapping was required for certain complex tables and relationships.
- Downtime: The business required the migration to happen over a weekend to minimize downtime.
Solutions Implemented
- Automated Mapping: Utilized automated mapping tools wherever possible to speed up the process.
- Verification: Post-migration verification ensured data integrity.
Frequently Asked Questions (FAQs)
What are the key steps in migrating from DBF to SQL?
The key steps include choosing the right conversion tool, assessing your DBF files, preparing the SQL Server database, installing and configuring the data migration tool, mapping the data, executing the conversion, and verifying the migrated data.
What challenges might I encounter during the migration?
Challenges may include data loss, data corruption, or incorrect data mapping. It’s crucial to have a rollback plan and thorough verification post-migration.
Which tools can aid in the DBF to SQL conversion process?
Tools like DBConvert, Full Convert, and SQL Server Migration Assistant can be helpful. Each has its own set of features and capabilities.
How do I handle large DBF files during conversion?
Splitting large DBF files into smaller chunks or using powerful conversion tools capable of handling large datasets can be beneficial.
How can I ensure data integrity post-migration?
Post-migration verification, data integrity checks, and validation of relationships are essential steps to ensure data integrity.

Database
The ORA-06512 error is a common yet critical issue encountered in Oracle PL/SQL programming. This error message essentially serves as a pointer, indicating the line number in the code where an unhandled exception has occurred. It’s part of a larger error stack that helps developers trace the source of the problem and, consequently, fix it. Understanding and resolving ORA-06512 errors is fundamental to maintaining the integrity and functionality of database systems built on Oracle technologies.
Key Takeaways:
ORA-06512 is an error pointer in Oracle PL/SQL programming, indicating the line of code where an unhandled exception has occurred.- A thorough understanding and resolution of
ORA-06512 errors are essential for the optimal performance of Oracle database systems.
Introduction to ORA-06512 Error
Definition and Significance of ORA-06512 Error
The ORA-06512 error is synonymous with Oracle PL/SQL programming. It’s a part of the Oracle error stack that gets generated whenever there’s an unhandled exception in the code. The key characteristic of this error is that it points out the exact line in the code where the exception has occurred, thereby serving as a useful debugging tool for developers.
Common Scenarios Leading to ORA-06512
The error message usually appears as part of a message stack, providing a trail for developers to follow and find the root cause of the issue. It’s crucial for Oracle PL/SQL developers to understand the circumstances under which this error occurs to prevent it from happening and to resolve it when it does occur.
Internal Resources:
Causes of ORA-06512 Error

www.tracedynamics.com
Delving into the common causes of the ORA-06512 error aids in a better understanding and quicker resolution. Some of these causes include:
- Syntax Errors: Syntax errors in the code can trigger exceptions leading to the
ORA-06512 error.
- Runtime Errors: Errors that occur during the execution of the program.
- Logical Errors: Errors in the logic of the code can also lead to unhandled exceptions.
By analyzing the error stack, developers can trace back to the source of the error, understand what went wrong, and take corrective measures.
Diagnosing the ORA-06512 Error
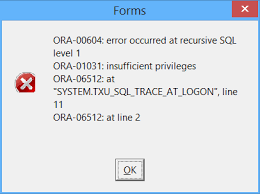
Identifying the Line Number
The line number provided by the ORA-06512 error is the starting point for diagnosing the problem. It tells developers exactly where to look in the code to find the unhandled exception.
Reading the Error Stack
The error stack is a collection of error messages that provide a trail to follow, leading back to the source of the error. Understanding how to read the error stack is crucial for diagnosing and resolving the ORA-06512 error.
Internal Resources:
Resolving the ORA-06512 Error
Common Solutions
The ORA-06512 error is resolvable by addressing the unhandled exception that triggered it. Some common solutions include:
- Fixing Syntax Errors: Correcting syntax errors in the code.
- Handling Exceptions: Including exception handling blocks in the code to catch and handle exceptions.
- Correcting Logical Errors: Fixing errors in the logic of the code.
Understanding the error and taking corrective measures is the path to resolving the ORA-06512 error and ensuring the smooth operation of Oracle database systems.
Preventing the ORA-06512 Error
Best Practices in PL/SQL Coding
Preventing the ORA-06512 error largely hinges on adhering to best practices in PL/SQL coding. Here are some preventive measures:
- Exception Handling: Incorporate exception handling blocks to catch and handle exceptions.
- Data Validation: Ensure data validation to prevent incompatible data type assignments.
- Code Review: Regular code reviews to identify and fix potential issues that could lead to errors.
Adhering to these best practices not only prevents ORA-06512 errors but also contributes to the overall robustness and reliability of the database system.
Internal Resources:
Advanced Troubleshooting

www.tracedynamics.com
Utilizing Oracle Tools
Oracle provides a suite of advanced tools that can be employed for troubleshooting the ORA-06512 error. These tools offer deeper insights into the database operations and help in identifying the root cause of the error.
- Oracle Debugger: Allows for step-by-step execution of code to identify where the error occurs.
- Error Log: The error log provides a detailed record of all errors that occur, including
ORA-06512.
- Trace Files: Trace files provide a detailed execution path, aiding in identifying the source of the error.
Leveraging these tools significantly aids in diagnosing and resolving ORA-06512 errors.
Case Studies
Real-world case studies provide a practical perspective on the occurrence and resolution of ORA-06512 errors in Oracle PL/SQL programming environments. By examining actual scenarios, readers can better understand the steps involved in diagnosing and resolving this common error.
Case Study 1: Unexpected Data Type Error
Scenario:
In a financial services firm, a PL/SQL program was developed to automate the calculation of monthly interest for all active accounts. However, upon deployment, the program threw an ORA-06512 error.
Diagnosis:
Upon reviewing the error stack, it was found that the error was triggered at a line where the program was attempting to divide a number by a string, an operation that is not allowed due to incompatible data types.
Resolution:
The developers corrected the data type of the variable involved, changing it from a string to a number. They also added an exception handling block to catch and handle any future data type errors, thus preventing the ORA-06512 error from occurring again.
Case Study 2: Missing Exception Handling
Scenario:
In a retail management system, a PL/SQL program was written to update inventory levels. However, when an item’s stock level fell below a critical threshold, the program failed with an ORA-06512 error.
Diagnosis:
The error stack pointed to a line of code where an exception was raised due to the stock level falling below the critical threshold. However, there was no exception handling block to catch and handle this exception, leading to the ORA-06512 error.
Resolution:
Developers added an exception handling block to catch the exception and send an alert to the inventory manager whenever the stock level of an item falls below the critical threshold. This not only resolved the ORA-06512 error but also improved the inventory management process by providing timely alerts.
Frequently Asked Questions (FAQs)
What is the ORA-06512 error and why is it significant?
The ORA-06512 error is an error message in Oracle PL/SQL that indicates the line number where an unhandled exception has occurred, aiding in debugging and resolution.
How can the ORA-06512 error be resolved?
The ORA-06512 error can be resolved by addressing the unhandled exception that triggered it. Common solutions include fixing syntax errors, handling exceptions, and correcting logical errors in the code.
What are the common causes of the ORA-06512 error?
Common causes of the ORA-06512 error include syntax errors, runtime errors, and logical errors in the code.
How can the ORA-06512 error be prevented?
The ORA-06512 error can be prevented by adhering to best practices in PL/SQL coding, such as incorporating exception handling blocks, ensuring data validation, and conducting regular code reviews.
What tools are available for diagnosing the ORA-06512 error?
Tools like the Oracle Debugger, Error Log, and Trace Files can be utilized for diagnosing the ORA-06512 error.

Database
ã˜â§ã˜â®ã˜â¨ã˜â§ã˜â± ã˜â¯ã™ë†ã™â€žã™å ã˜â© facing this strange character problem?
In the realm of data handling, character encoding holds a pivotal role ensuring textual data remains intact and legible throughout its lifecycle. However, encoding mismatches can lead to garbled text or strange characters, a common anomaly that often perplexes developers. This article delves into the intricacies of character encoding, drawing insights from community experiences and discussions.
Understanding the Core of Character Encoding
Character encoding is a set of rules that map characters to numbers. It’s the backbone that ensures text remains legible when stored in databases, transferred between systems, or rendered on screens.
The Significance of Correct Encoding
- Data Integrity: Correct encoding preserves the original text, ensuring data integrity.
- Legibility: It ensures text is legible when retrieved or displayed.
- Interoperability: Encoding standards promote interoperability between different systems.
Common Encoding Standards
- ASCII: A 7-bit character encoding standard representing 128 characters.
- ISO-8859-1: A 8-bit character encoding standard representing 256 characters.
- UTF-8: A variable-width character encoding standard capable of encoding all possible characters, or code points, in Unicode.
The Phenomenon of Strange Characters
When character encoding mismatches occur, they often manifest as strange or garbled characters in text. This is a tell-tale sign of encoding discrepancies during data handling.
Common Scenarios
- Database Storage: Incorrect encoding settings in databases can cause text to be stored incorrectly.
- Data Transmission: Encoding mismatches during data transmission can garble text.
- Rendering: Incorrect encoding at the rendering stage can lead to strange characters on the screen.
Decoding the Query
The ã˜â§ã˜â®ã˜â¨ã˜â§ã˜â± ã˜â¯ã™ë†ã™â€žã™å ã˜â© in focus highlights a typical scenario where strange characters appear in database text, hinting at a possible UTF-8 encoding and decoding mismatch.
Community Insights
The community suggests that somewhere in the process of handling text data, a mismatch in UTF-8 encoding and decoding could be the culprit.
Practical Implications
This real-world example underscores the importance of ensuring encoding consistency across all stages of data handling.
Strategies for Tackling Encoding Mismatches
Addressing encoding mismatches necessitates a thorough understanding of the encoding processes involved and a methodical approach to identifying and rectifying the issues.
Database Configuration
- Check Encoding Settings: Ensure the database is configured to use the correct character encoding.
- Use Unicode: If possible, use a Unicode encoding like UTF-8 to accommodate a wide range of characters.
Data Transmission
- Specify Encoding: When transmitting data, specify the encoding being used to avoid mismatches.
- Validation: Validate the encoding at both ends of the transmission to ensure consistency.
Rendering
- Meta Tags: Use meta tags to specify the character encoding in HTML documents.
- Content-Type Headers: Specify the character encoding in the Content-Type headers.
Conclusion
Character encoding mismatches can lead to perplexing scenarios where text data appears as strange characters. By understanding the fundamentals of character encoding and adopting a systematic approach to identifying and addressing encoding issues, developers can ensure data integrity, legibility, and smooth interoperability between systems.
Frequently Asked Questions
1. What causes strange characters like ã˜â§ã˜â®ã˜â¨ã˜â§ã˜â± ã˜â¯ã™ë†ã™â€žã™å ã˜â© to appear in database text?
- Strange characters often appear due to mismatches in character encoding either when storing, transmitting, or rendering text data. This usually happens when the encoding standard used to store the data differs from the one used to read or display the data.
2. How can I prevent encoding mismatches that lead to strange characters in my database text?
- Ensuring consistency in the character encoding standards used across all stages of data handling can prevent encoding mismatches. It’s advisable to use Unicode encodings like UTF-8, specify encoding settings in your database configuration, and also specify the character encoding in HTML documents and data transmission protocols.
3. Are certain databases more prone to character encoding issues?
- Encoding issues can arise in any database if the character encoding settings are not configured correctly or inconsistently handled. However, the ease of configuring and managing encoding settings may vary across different database systems.
4. How can I identify the character encoding used to store text in my database?
- Most databases provide system variables or metadata queries that can be used to check the character encoding settings. You can also use database management tools or consult the documentation of your database system to find out how to check and change character encoding settings.
5. Can encoding mismatches cause data loss or corruption?
- Yes, encoding mismatches can potentially cause data corruption, especially if text data is incorrectly decoded or re-encoded using a different character encoding standard. It’s crucial to address encoding issues promptly to prevent data loss and ensure data integrity.
These FAQs provide a quick insight into common queries and concerns regarding character encoding issues, especially when strange characters appear in database text.
